
阿里云开发者社区






大家在互动










综合
最新
有奖励
免费用

社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
Arm 架构的服务器通常具备低功耗的特性,能带来更优异的能效比。相比于传统的 x86 架构服务器,Arm 服务器在相同功耗下能够提供更高的性能。这对于大模型推理任务来说尤为重要,因为大模型通常需要大量
让你的文档从静态展示到一键部署可操作验证
通过函数计算的能力让阿里云的文档从静态展示升级为动态可操作验证,用户在文档中单击一键部署可快速完成代码的部署及测试。这一改变已在函数计算的活动沙龙中得到用户的认可。
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
本教程将带领大家免费领取阿里云PAI-EAS的免费试用资源,并且带领大家在 ComfyUI 环境下使用 SVD的模型,根据任何图片生成一个小短视频。
一文解读:阿里云AI基础设施的演进与挑战
对于如何更好地释放云上性能助力AIGC应用创新?“阿里云弹性计算为云上客户提供了ECS GPU DeepGPU增强工具包,帮助用户在云上高效地构建AI训练和AI推理基础设施,从而提高算力利用效率。”李
PAI-EAS 一键启动ComfyUI!SVD 图片一键生成视频 stable video diffusion 教程 SVD工作流
PAI-EAS 一键启动ComfyUI!SVD 图片一键生成视频 stable video diffusion 教程 SVD工作流

乘风问答官5月排位赛开启!
2024年5月起乘风问答官专属活动全新起航鼓励问答官们积极给予高质量的解答和参与讨论给社区带来更好的体验~2024年5月问答官专属每周积分活动、每月排位赛开启欢迎问答官们参与。 面对对象 所有乘风问

一文解析 ODPS SQL 任务优化方法原理
本文重点尝试从ODPS SQL的逻辑执行计划和Logview中的执行计划出发,分析日常数据研发过程中各种优化方法背后的原理,覆盖了部分调优方法的分析,从知道怎么优化,到为什么这样优化,以及还能怎样优化
表单新加了个字段A,历史数据要添加字段A的值问题
表单新加了个字段A历史数据要添加字段A的值管理页的批量修改这种方式是否是目前最好的方式了尝试过通过api接口的方式速度是快的但更新后只能在列表页看到字段A的数据详情页是看不到字段A的数据的。研究了下
飞 天 技 术 沙 龙 | AI 原 生 应 用 架 构 专 场

代码管理实践10讲
本书旨在为读者提供做好代码评审、分支、安全惯例的实践技巧。内容由阿里云云效代码团队编制,主要面向开发工程师、测试工程师和技术管理者,以提升整个开发过程中的代码质量和安全性。

【云效流水线 Flow 测评】驾驭云海:五大场景下的云效Flow实战部署评测
云效是一款企业级持续集成和持续交付工具,提供免费、高可用的服务,集成阿里云多种服务,支持蓝绿、分批、金丝雀等发布策略。其亮点包括快速定位问题、节省维护成本、丰富的企业级特性及与团队协作的契合。基础版和
10倍性能提升-SLS Prometheus 时序存储技术演进
本文将介绍近期SLS Prometheus存储引擎的技术更新,在兼容 PromQL 的基础上实现 10 倍以上的性能提升。同时技术升级带来的成本红利也将回馈给使用SLS 时序引擎的上万内外部客户。
OpenKruise v1.6 版本解读:增强多域管理能力
OpenKruise 在 2024.3 发布了最新的 v1.6 版本(ChangeLog),本文对新版本的核心特性做整体介绍。
手把手教你捏一个自己的Agent
Modelscope AgentFabric是一个基于ModelScope-Agent的交互式智能体应用,用于方便地创建针对各种现实应用量身定制智能体,目前已经在生产级别落地。
Serverless 成本再优化:Knative 支持抢占式实例
Knative 是一款云原生、跨平台的开源 Serverless 应用编排框架,而抢占式实例是公有云中性价比较高的资源。Knative 与抢占式实例的结合可以进一步降低用户资源使用成本。本文介绍如何在
别emo,EMO来了!你的照片也能开口讲相声、飙情歌
阿里云推出AI面部驱动工具EMO,可在通义APP的【全民舞台】体验。用户上传图片,选择模板即可生成动态说话效果。目前模板丰富,包括《野狼Disco》等,但因体验者众多,生成时间约10分钟。EMO由阿里
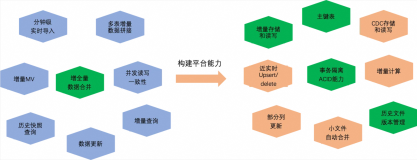
MaxCompute 近实时增全量处理一体化新架构和使用场景介绍
本文主要介绍基于 MaxCompute 的离线近实时一体化新架构如何来支持这些综合的业务场景,提供近实时增全量一体的数据存储和计算(Transaction Table2.0)解决方案。
Llama 3开源!魔搭社区手把手带你推理,部署,微调和评估
Meta发布了 Meta Llama 3系列,是LLama系列开源大型语言模型的下一代。在接下来的几个月,Meta预计将推出新功能、更长的上下文窗口、额外的模型大小和增强的性能,并会分享 Llama


Python 学习之路 01基础入门---【Python安装,Python程序基本组成】
线程池详解与异步任务编排使用案例-xian-cheng-chi-xiang-jie-yu-yi-bu-ren-wu-bian-pai-shi-yong-an-li
javpower:后端技术革新的开源之旅
? Java后端开发者javpower热衷于开源项目,分享AI、Git、Redis等领域的知识和工具,如JavaVision、EasyGit。擅长JVM优化、数据库事务处理、微服务架构等,积极参与开
谈谈我对 AIGC 趋势下软件工程重塑的理解
本文探讨了AIGC(人工智能生成内容)趋势下软件工程的重塑。作者指出,AI 已经成为软件研发的必需品,因为它可以显著提升开发者的效率。
深入理解Java并发编程:线程安全与性能优化
【4月更文挑战第15天】在Java开发中,多线程编程是提升应用程序性能和响应能力的关键手段。然而,它伴随着诸多挑战,尤其是在保证线程安全的同时如何避免性能瓶颈。本文将探讨Java并发编程的核心概念,包
抖音最近很火的QQ在线价值评估网站源码(qq价值在线评估)
这个源码是很多年以前的了,最近又在抖音刷到别人直播需要刷礼物才能给你评测,所以又找了一下测试了可用,将源码上传后解压,访问可以直接使用。

得物 ZooKeeper SLA 也可以 99.99%丨最佳实践
在本文中,作者探讨了ZooKeeper(ZK)的一个内存占用问题,特别是当有大量的Watcher和ZNode时,导致的内存消耗。
Phi-3:小模型,大未来!(附魔搭社区推理、微调实战教程)
近期, Microsoft 推出 Phi-3,这是 Microsoft 开发的一系列开放式 AI 模型。Phi-3 模型是一个功能强大、成本效益高的小语言模型?(SLM),在各种语言、推理、编码和数学
MaxCompute产品使用合集之大数据计算MaxCompute如何实现通过离线同步脚本模式
MaxCompute作为一款全面的大数据处理平台,广泛应用于各类大数据分析、数据挖掘、BI及机器学习场景。掌握其核心功能、熟练操作流程、遵循最佳实践,可以帮助用户高效、安全地管理和利用海量数据。以下是
Golang框架实战-KisFlow流式计算框架(2)-项目构建/基础模块-(上)
KisFlow项目源码位于<https://github.com/aceld/kis-flow,初始阶段涉及项目构建和基础模块定义。首先在GitHub创建仓库,克隆到本地。项目目录包括`comm

MaxCompute产品使用合集之大数据计算MaxCompute底层加速查询的原理是什么
MaxCompute作为一款全面的大数据处理平台,广泛应用于各类大数据分析、数据挖掘、BI及机器学习场景。掌握其核心功能、熟练操作流程、遵循最佳实践,可以帮助用户高效、安全地管理和利用海量数据。以下是
千亿大模型来了!通义千问110B模型开源,魔搭社区推理、微调最佳实践
近期开源社区陆续出现了千亿参数规模以上的大模型,这些模型都在各项评测中取得杰出的成绩。今天,通义千问团队开源1100亿参数的Qwen1.5系列首个千亿参数模型Qwen1.5-110B,该模型在基础能力
Java中的多线程编程:概念、实现与性能优化
【4月更文挑战第9天】在Java编程中,多线程是一种强大的工具,它允许开发者创建并发执行的程序,提高系统的响应性和吞吐量。本文将深入探讨Java多线程的核心概念,包括线程的生命周期、线程同步机制以及线
Java线程池ThreadPoolExcutor源码解读详解08-阻塞队列之LinkedBlockingDeque
**摘要:** 本文分析了Java中的LinkedBlockingDeque,它是一个基于链表实现的双端阻塞队列,具有并发安全性。LinkedBlockingDeque可以作为有界队列使用,容量由构
SLS 查询新范式:使用 SPL 对日志进行交互式探索
像 Unix 命令一样支持多级管道级联,像加工预览一样实时处理查询结果,更便捷的交互,更丰富的算子,更灵活的探索半结构化日志,快来试试使用 SPL 语言查询日志数据吧~
Java线程池ThreadPoolExcutor源码解读详解07-阻塞队列之LinkedTransferQueue
`LinkedTransferQueue`是一个基于链表结构的无界并发队列,实现了`TransferQueue`接口,它使用预占模式来协调生产者和消费者的交互。队列中的元素分为数据节点(isData为
线程同步的艺术:探索 JAVA 主流锁的奥秘
本文介绍了 Java 中的锁机制,包括悲观锁与乐观锁的并发策略。悲观锁假设多线程环境下数据冲突频繁,访问前先加锁,如 `synchronized` 和 `ReentrantLock`。乐观锁则在访问资
社区供稿 | Llama3-8B中文版!OpenBuddy发布新一代开源中文跨语言模型
此次发布的是在3天时间内,我们对Llama3-8B模型进行首次中文跨语言训练尝试的结果:OpenBuddy-Llama3-8B-v21.1-8k。
大数据计算MaxCompute调度资源组是不是分配任务,公共的有下架计划嘛?
大数据计算MaxCompute调度资源组是不是分配任务生成mr任务和计算的时候使用的。调度资源组下公共的有下架计划嘛数据服务资源组是干嘛的
移动应用开发的未来趋势与移动操作系统的创新动向
【5月更文挑战第3天】随着智能手机的普及和移动互联网的快速发展,移动应用(App)已成为人们日常生活中不可或缺的一部分。本文将探讨移动应用开发的最新趋势,包括跨平台开发的流行、人工智能的集成以及安全性
探索自动化测试在持续集成中的关键作用
【5月更文挑战第3天】 随着敏捷开发和持续集成(CI)实践的普及,自动化测试已成为确保软件质量和加速交付过程的核心环节。本文旨在深入探讨自动化测试在持续集成环境中的作用,重点分析其在提高测试效率、降低
pytorch与深度学习
【5月更文挑战第3天】PyTorch,Facebook开源的深度学习框架,以其动态计算图和灵活API深受青睐。本文深入浅出地介绍PyTorch基础,包括动态计算图、张量和自动微分,通过代码示例演示简单
大数据计算MaxCompute如何查看当前项目参数配置的数值啊?
大数据计算MaxCompute如何查看当前项目set odps.merge.maxmerged.filesize.threshold 参数配置的数值啊
大数据计算MaxCompute数据太大用不了to_pandas(),格式的数据咋转换呢?
大数据计算MaxCompute数据太大用不了to_pandas()我想用sklearn的算法需要array格式的数据PyODPS DataFrame格式的数据咋转换呢
大数据计算MaxCompute有个string类型的日期,为一些为空的,这样的我怎么处理?
大数据计算MaxCompute有个string类型的日期为一些为空的但是我想转成日期进行to_date操作但是空的会提示报错。ODPS-0121095:Invalid argument - in f
大数据计算MaxCompute在SQL中使用这种笛卡尔join(不加on条件),应该怎么设置?
大数据计算MaxCompute在SQL中使用这种笛卡尔join不加on条件应该怎么设置喃我红框那个表就只有一条数据的
大数据计算MaxCompute这两个命令都试了,都未起作用为什么?
大数据计算MaxCompute这两个命令都试了都未起作用set mapred.reduce.tasks1000; set odps.sql.reducer.instances 1000; 有 最后的
大数据计算MaxCompute这边执行sql语句,在某个步骤实例数量只有1个,这个可以调节吗?
大数据计算MaxCompute这边执行sql语句在某个步骤实例数量只有1个导致运行速度很慢这个可以调节吗
大数据计算MaxCompute继承的UDTF为什么会找不到evaluate方法?
大数据计算MaxCompute继承的UDTF为什么会找不到evaluate方法这个方法是UDF里面的方法啊用UDTF函数返回的Array〈string〉类型数据http://logview.odps
大数据计算MaxCompute这条参数的运行格式是怎样的?
大数据计算MaxCompute这条参数的运行格式是怎样的set odps.sql.executionengine.streamlinex.enable.alltrue
大数据计算MaxCompute中dataframe 怎么分批次读取数据呢?
大数据计算MaxCompute中dataframe 怎么分批次读取数据呢 DataFrame object has no attribute offset
大数据计算MaxCompute让申请使用 copytask ,还需要保证网络互通。帮忙看看?
大数据计算MaxCompute让申请使用 copytask 还需要保证网络互通。我怎么知道我的金融云 maxcompute 和 公有云 maxcompute 是不是同一个内网都在 杭州
大数据计算MaxCompute这个是不是没办法控制的?
大数据计算MaxCompute这个是不是没办法控制的我就一条insert into 语句都能错成这样failed: ODPS-0110061: Failed to run ddltask - Alr
云端之盾:构建云计算环境下的网络安全防线
【5月更文挑战第3天】 在数字化转型的浪潮中,云计算作为企业IT架构的核心,提供了弹性、可扩展的资源和服务。然而,随着数据和应用不断向云端迁移,网络安全威胁也随之增加,给企业带来了前所未有的挑战。本文
利用深度学习优化图像识别处理流程
【5月更文挑战第3天】 在现代技术环境中,图像识别作为人工智能的一个关键应用领域,其发展速度和准确性要求不断提高。本文将探讨利用深度学习技术优化图像识别处理流程的方法,包括数据预处理、模型选择、训练策
大数据计算MaxCompute中pyrhon引入odps包一直显示cannot 这个有解决办法么?
大数据计算MaxCompute中pyrhon引入odps包一直显示cannot import ODPS from odps目前是python 3.9版本这个有解决办法么pyodps 0.11.6版本
大数据计算MaxCompute迁 maxcompute 不用 hive ,就下一个最新版就行吧?
大数据计算MaxCompute迁 maxcompute 不用 hive ,就下一个最新版就行吧
大数据计算MaxCompute申请开通分层功能后,若不使用,对项目中其他查询/写入性能没有影响吧?
大数据计算MaxCompute申请开通分层功能后若不使用对项目中其他查询/写入性能没有影响吧 如果部分表使用其稳定性 不影响生产环境的表使用吧
大数据计算MaxCompute金融云迁移到公有云,只在阿里云内部迁移使用。要不要安装 mma 工具?
大数据计算MaxCompute金融云迁移到公有云只在阿里云内部迁移使用。要不要安装 mma 工具
大数据计算MaxCompute分层存储 上周四申请了此功能使用资格,不知道何时能使用?
大数据计算MaxCompute分层存储 上周四申请了此功能使用资格至今还未收到短信不知道何时能使用test_hozon_dev 和 hozonods_dev 华东2上海

